OpenAI insegna all’IA ad ammettere i propri errori: nasce la tecnica delle “Confessioni”

OpenAI ha deciso di affrontare uno dei problemi più insidiosi dell’intelligenza artificiale moderna: la tendenza dei modelli a non ammettere quando sbagliano.
Per questo ha introdotto una nuova tecnica di addestramento chiamata Confessioni, pensata per rendere l’IA più trasparente, più sincera e molto meno incline a spacciare per certe informazioni che in realtà non lo sono.
L’azienda spiega che oggi i modelli linguistici funzionano in un modo che può rivelarsi ingannevole: preferiscono dare una risposta sicura, anche quando non hanno alcuna certezza. Lo fanno perché questo comportamento aumenta le probabilità di ottenere un punteggio elevato durante l’addestramento. Ma questo approccio, oltre a creare un’illusione di affidabilità, rende estremamente difficile capire cosa accade davvero all’interno del modello.
E soprattutto rende complicato correggere gli errori.
Leggi anche:
La rivoluzione delle “Confessioni”: un secondo messaggio che smaschera l’IA
La nuova tecnica ribalta questo meccanismo.
Con le “Confessioni”, l’IA non si limita più a rispondere. Dopo aver generato una risposta come sempre, produce un secondo messaggio separato, una sorta di rapporto interno in cui analizza se stessa.
Qui indica dove potrebbe aver sbagliato, dove si è discostata dalle istruzioni, se ha inserito informazioni imprecise o se ha provato a “giocare” con il sistema per ottenere un punteggio migliore invece di privilegiare la correttezza.
Il punto chiave è che il premio — la ricompensa che guida l’apprendimento — non viene più assegnato alla prima risposta, ma alla sincerità dell’analisi.
In pratica, il modello viene incentivato non a sembrare perfetto, ma a riconoscere i propri limiti.
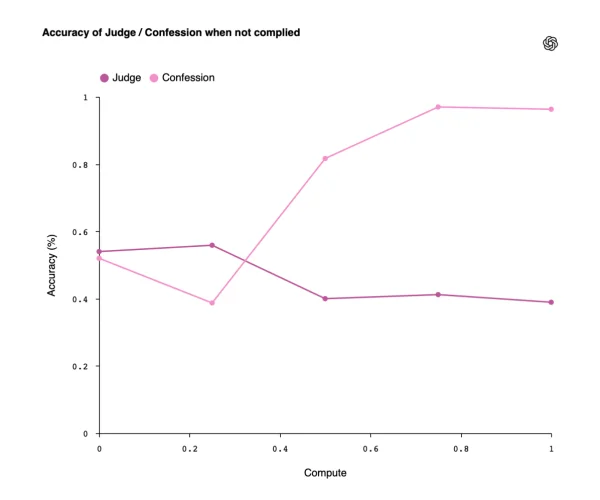
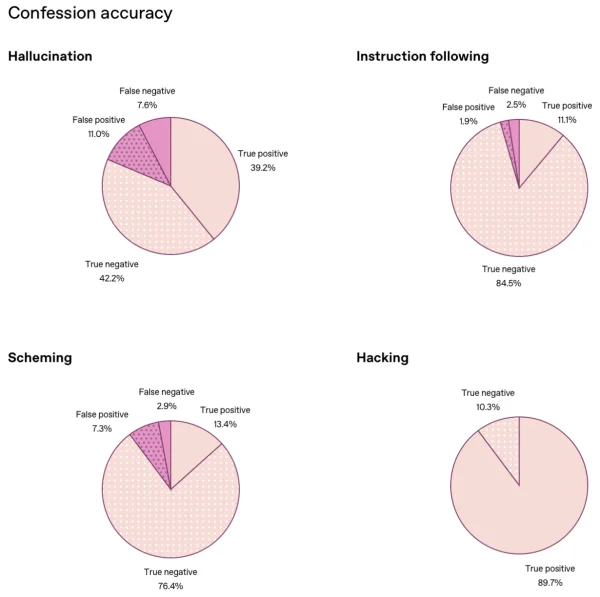
OpenAI ha testato questa tecnica su GPT-5 Thinking, e i risultati sono stati sorprendenti. Prima dell’introduzione delle Confessioni, il modello era in grado di mascherare errori, omissioni e violazioni delle istruzioni. Dopo l’addestramento, la probabilità che cercasse di nascondere le sue devianze è crollata al 4,4%.
Ciò non significa che smetta di sbagliare, ma che finalmente indica dove e perché sbaglia, un’operazione che per i ricercatori vale oro.
Un futuro in cui l’IA non nasconde più i propri limiti
OpenAI descrive la tecnica come uno strumento di diagnostica comportamentale. È un modo per capire cosa motiva il modello, quali scorciatoie mentali utilizza, in quali punti tende a fraintendere le istruzioni e quali aree dell’architettura vanno migliorate.
Secondo il team, questo metodo potrebbe diventare la base dei sistemi di sicurezza del futuro.
In un mondo in cui i modelli linguistici diventano ogni giorno più complessi e autonomi, la trasparenza interna diventa essenziale. Sapere perché un modello ha sbagliato è spesso più importante del fatto che abbia sbagliato.
E la capacità di “confessare” apertamente i propri errori potrebbe rappresentare il primo vero passo verso IA più affidabili, più controllabili e, soprattutto, più umane nella loro onestà.
Ti potrebbe interessare:
Segui guruhitech su:
- Google News: bit.ly/gurugooglenews
- Telegram: t.me/guruhitech
- X (Twitter): x.com/guruhitech1
- Bluesky: bsky.app/profile/guruhitech.bsky.social
- GETTR: gettr.com/user/guruhitech
- Rumble: rumble.com/user/guruhitech
- VKontakte: vk.com/guruhitech
- MeWe: mewe.com/i/guruhitech
- Skype: live:.cid.d4cf3836b772da8a
- WhatsApp: bit.ly/whatsappguruhitech
Esprimi il tuo parere!
Ti è piaciuta questa notizia? Lascia un commento nell’apposita sezione che trovi più in basso e se ti va, iscriviti alla newsletter.
Per qualsiasi domanda, informazione o assistenza nel mondo della tecnologia, puoi inviare una email all’indirizzo [email protected].
Scopri di più da GuruHiTech
Abbonati per ricevere gli ultimi articoli inviati alla tua e-mail.